

Data ELT กระบวนการเตรียมข้อมูลให้พร้อมสำหรับงาน Data Analytics
Data Extraction – Load – Transformation (ELT) for Data Analytics

MSc (cand.scient.), BA Hons (Cantab), CIPM
Deputy Director of Siriraj Informatics and Data Innovation Center (SiData+)
ในแต่ละองค์กรย่อมมีข้อมูลหลากหลายเรื่อง จากแหล่งข้อมูลต่าง ๆ จำนวนมาก ถ้าถามว่า "สามารถนำข้อมูลจากแหล่งต้นทางเหล่านี้มาใช้สำหรับงานวิเคราะห์ตรง ๆ เลยจะได้ไหม" ก็ต้องตอบว่า "ได้ ...แต่ไม่มีประสิทธิภาพ" เพราะจะเจอกับประเด็นต่าง ๆ เช่น
ต้องมาอัพเดทข้อมูลให้เป็นปัจจุบันเอง (ถ้าต้องการข้อมูลเพื่อตอบปัญหาครั้งเดียวจบ ก็จะไม่มีปัญหานี้)
ข้อมูลแต่ละระบบเก็บไม่เหมือนกัน เช่น ข้อมูลเดียวกันแต่ชื่อ column/field ไม่เหมือนกัน (ตัวอย่าง รหัสบุคลากรอาจจะเก็บเป็น EmployeeID, empID, employee_no) หรือ ชื่อ column/field เดียวกันแต่เนื้อข้อมูลต่างกัน (ตัวอย่าง employee_type อาจหมายถึง ประเภทการจ้างงาน, ประเภทบุคลากร, ประเภทเงินเดือน เป็นต้น)
ข้อมูลที่เก็บที่ต้นทาง หรือ application database มักจะถูก design มาสำหรับการใช้งานในรูปแบบ transaction ซึ่งมีความต้องการแตกต่างจากการวิเคราะห์ analytics ที่อาจจะต้องมีการคำนวน และการเชื่อมโยงกับข้อมูลอื่น ๆ เพิ่มเติม
การตรวจสอบความถูกต้องของข้อมูล จะทำให้ผู้ใช้งานข้อมูลเชื่อมั่นได้อย่างไรว่า ข้อมูลมีความถูกต้อง เป็นปัจจุบัน ไม่หาย ไม่ซ้ำ
การรักษาความปลอดภัย (security) และความเป็นส่วนตัว (privacy) ของข้อมูลที่กระจัดกระจายอยู่ จะทำให้ควบคุมการใช้งานได้ยาก และเมื่อมีกฎหมายทั้ง พ.ร.บ. Cybersecurity และ PDPA ต้องยิ่งควบคุมให้ดี มิเช่นนั้นก็จะมีบทลงโทษต่อองค์กร
จากตัวอย่างประเด็นข้างต้น กระบวนการ ELT จะเข้ามาช่วยคลี่คลายประเด็นเหล่านี้ และช่วยให้การจัดการ Data มีประสิทธิภาพมากยิ่งขึ้น
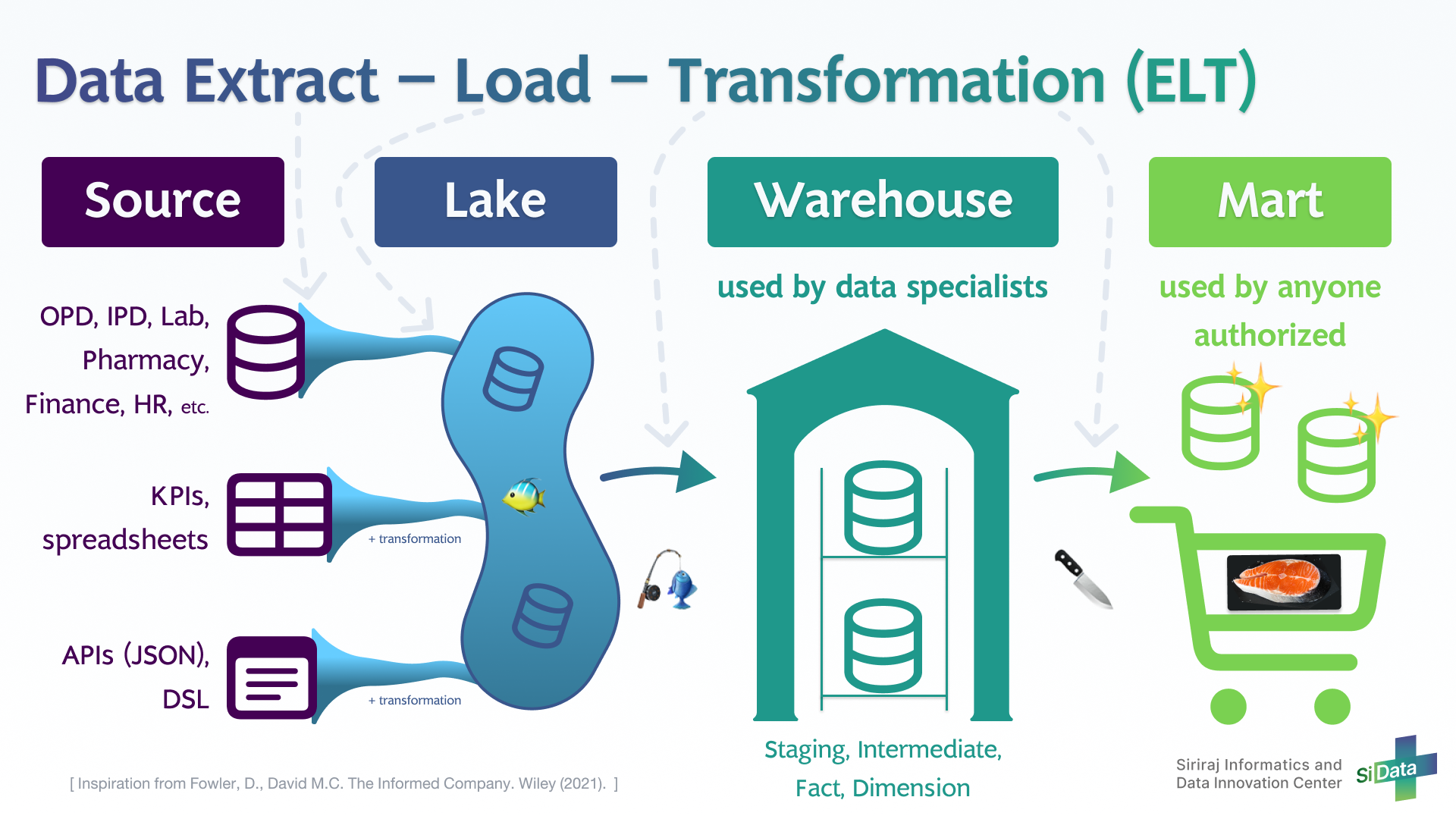
Source
ในศิริราช มีข้อมูลอยู่ 3 แหล่งหลัก ๆ
Databases ที่เก็บข้อมูลจากระบบในโรงพยาบาลต่าง ๆ เช่น OPD, IPD, Lab, Pharmacy, Finance, HR และอื่น ๆ
Spreadsheets ข้อมูลที่เก็บในไฟล์เป็นตาราง เช่น ตัวชี้วัด KPIs จากหน่วยงานต่าง ๆ, ระบบเก็บข้อมูลที่ไม่ใช่ Database เป็นต้น
APIs ที่คืนค่ามาเป็น JSON ผ่านระบบ Data Service Layer (DSL) ซึ่งเป็น integration gateway กลาง เชื่อมโยงข้อมูลจากระบบต่าง ๆ มาส่งให้ เช่น Data Registry เป็นต้น
กรณี Databases (NoSQL), Spreadsheets, APIs จะมีการแปลงข้อมูล (Transformation) ให้อยู่ในรูปแบบ Tabular relations (SQL-compatible)
แต่ละ source เปรียบเสมือน ปลา แต่ละชนิด ใน 1 แม่น้ำ
Data Lake
นำข้อมูลออกมาจาก source ต่าง ๆ (Extract) มารวมกันในแหล่งเดียว เพื่อให้ง่ายต่อการจัดการ และเมื่อแยกส่วนออกจาก Application Database การทำงานใน Data Lake ก็จะไม่ไปกระทบกับ Database ต้นทาง
เปรียบเสมือน ปลาหลายชนิด จาก หลายแม่น้ำ ไหลมารวมกัน (Extract & Load) ในทะเลสาบ (Lake)
Data Warehouse
นำข้อมูลจาก Lake มาจัดระเบียบและแปลงโครงสร้าง (Transformation) ให้อยู่ในรูปแบบที่สามารถนำข้อมูลไปใช้ต่อได้ง่ายขึ้น เช่น Unified Star Schema, OMOP CDM เป็นต้น โดยอาจมีการนำ Data จากหลาย table มาเชื่อมโยงกัน (Join) เพื่อเติมข้อมูลให้สมบูรณ์ขึ้น และจัดวางบน shelf ชั้นวางในคลังข้อมูลให้เรียบร้อย
ในขั้นนี้สามารถเริ่มนำ Data ไปใช้งานต่าง ๆ เช่น การทำ Dashboard, การทำ ML & AI เป็นต้น ได้บ้างแล้ว แต่ยังต้องอาศัยผู้ที่มีความเข้าใจข้อมูลพอสมควรในการใช้งาน เช่น การ Join, Group By, Pivot เป็นต้น
เปรียบเสมือน ทีม Data specialists ที่มีความรู้ในการตกปลา (Transformation) ไปจับปลาชนิดที่ต้องการ มาเก็บไว้ในคลัง
Data Mart
นำข้อมูลจาก Data Warehouse มาปรับโครงสร้าง ให้พร้อมใช้งานได้มากที่สุด โดยที่ผู้ใช้งานที่ได้รับอนุญาตสามารถหยิบข้อมูลควบคู่กับคำอธิบายไปใช้ได้โดยง่าย
เปรียบเสมือน ทีม Data specialists แล่ปลา (Transformation) ให้พร้อมไปวางขายใน supermarket ทำให้ผู้ใช้งานข้อมูล (Data users) สามารถซื้อไปปรุงอาหารต่อได้ง่าย (Data products) โดยที่ไม่ต้องตกปลาหรือแล่ปลาเป็น
แนะนำแหล่งศึกษาเพิ่มเติม




